Chapter 1
Humans & Books






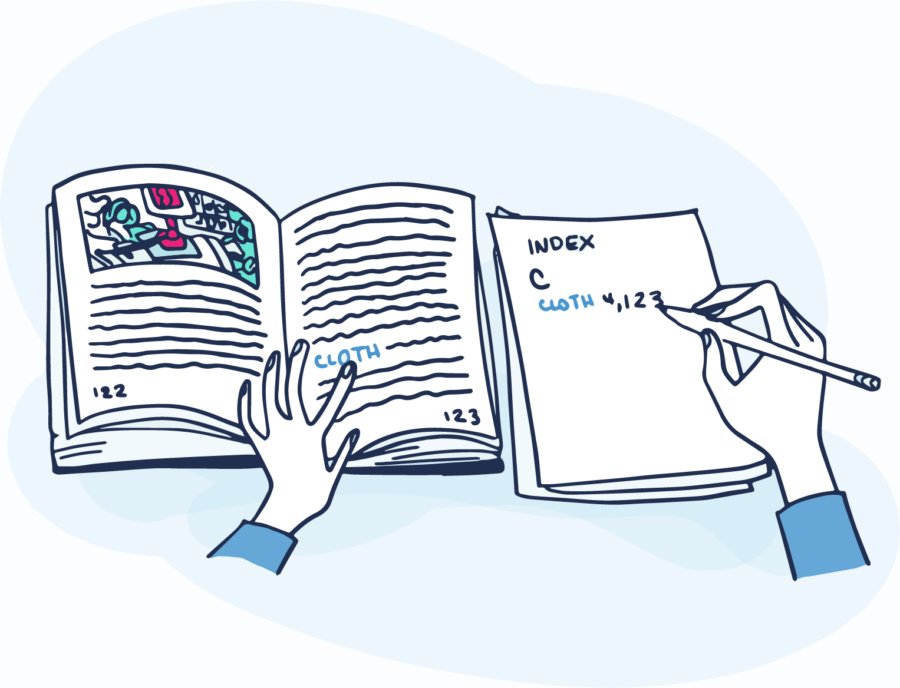
the Index!


Chapter 2
Computers & Databases
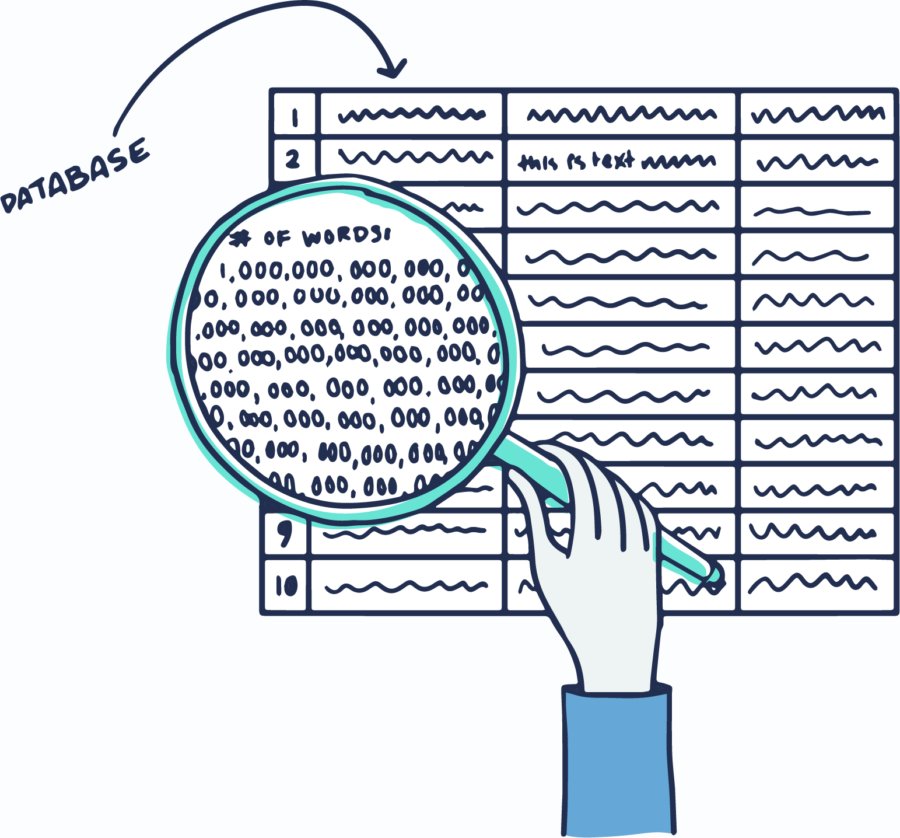




the Index!


Chapter 3
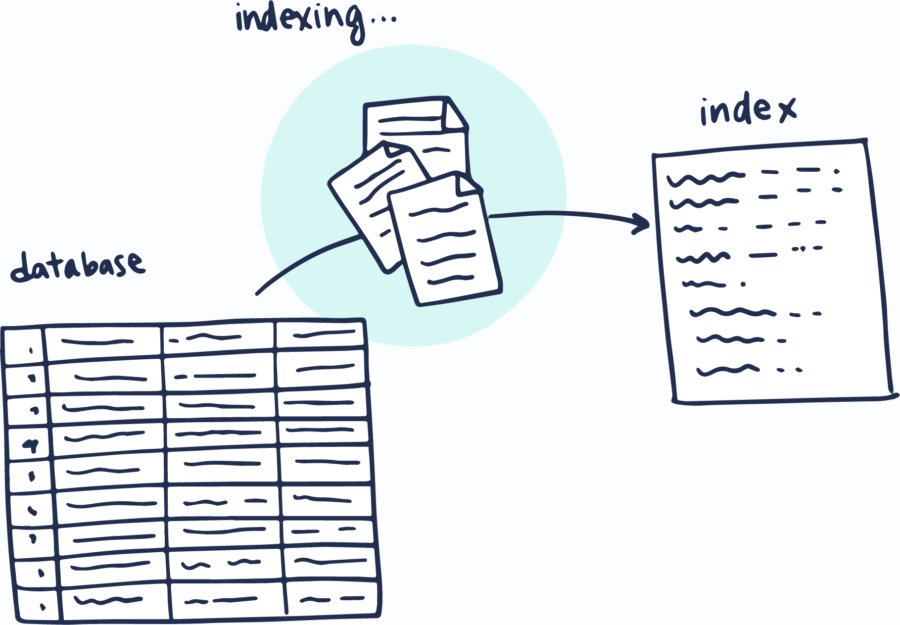
Create an Index

Click on the button below to see how we create indices.

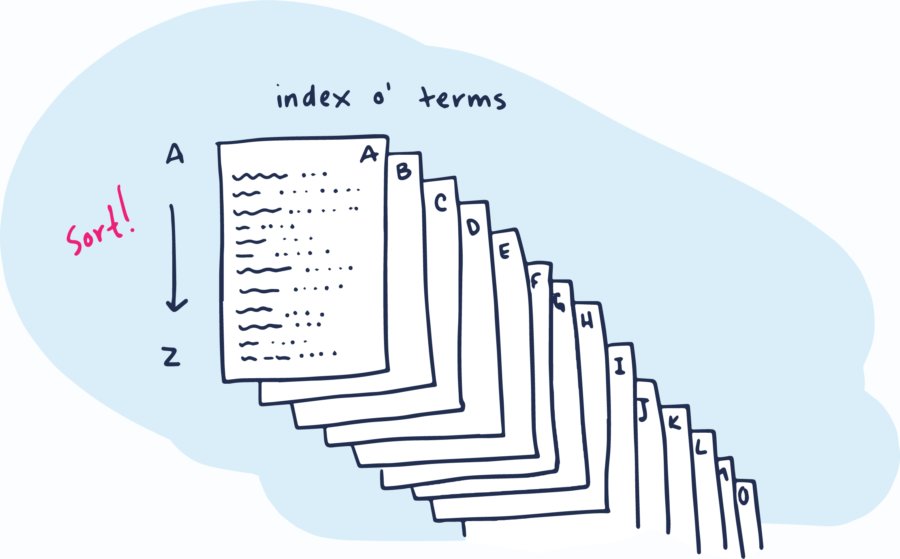
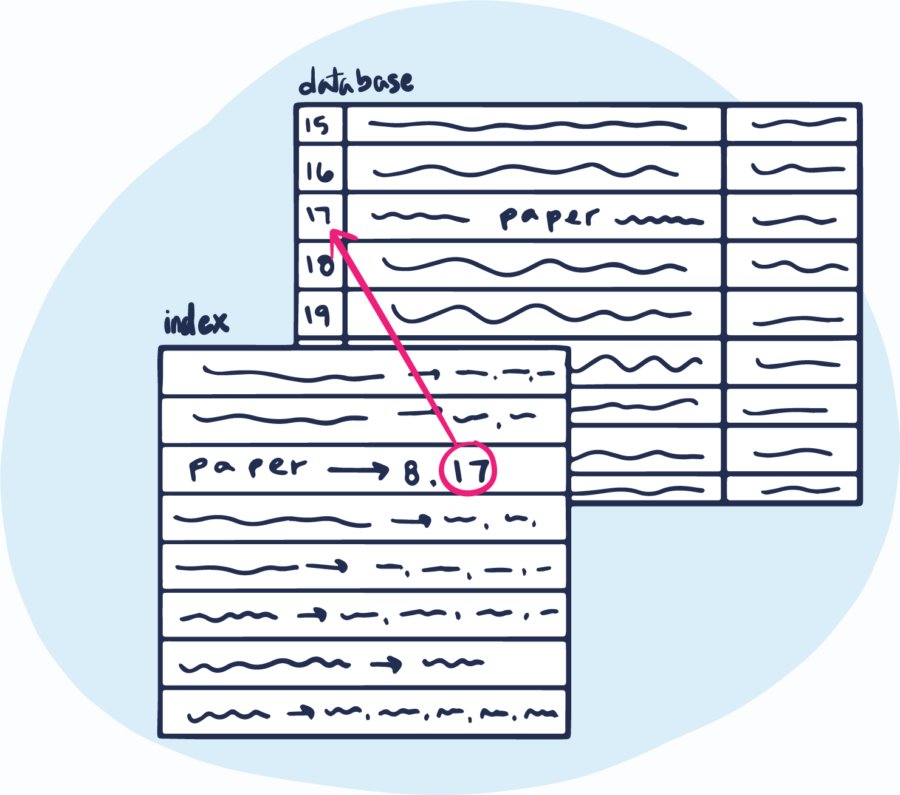
Indexing transforms raw text into a set of "tokens". Tokens are added to the index with a reference to each document containing the token.

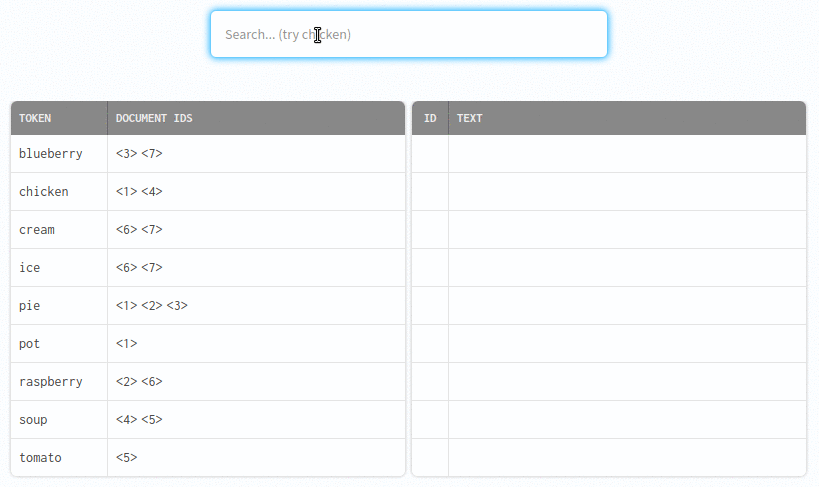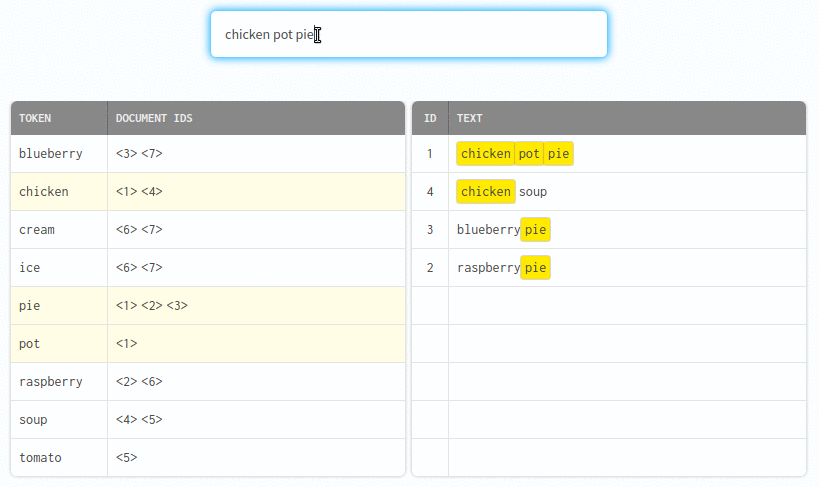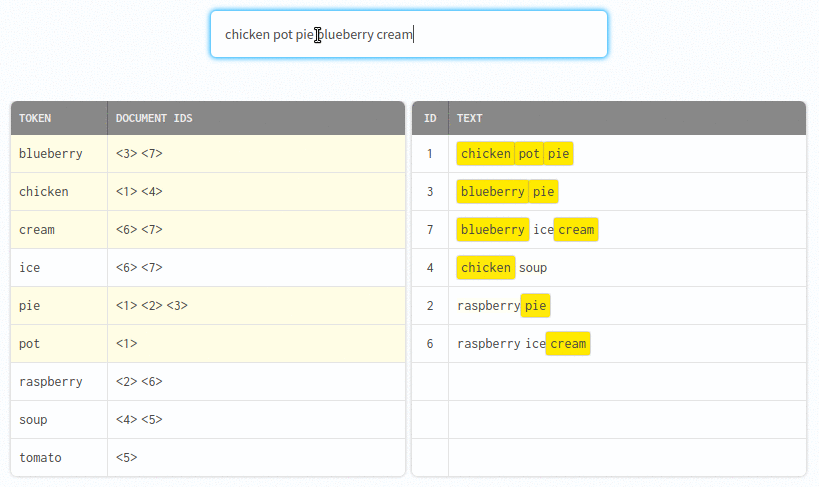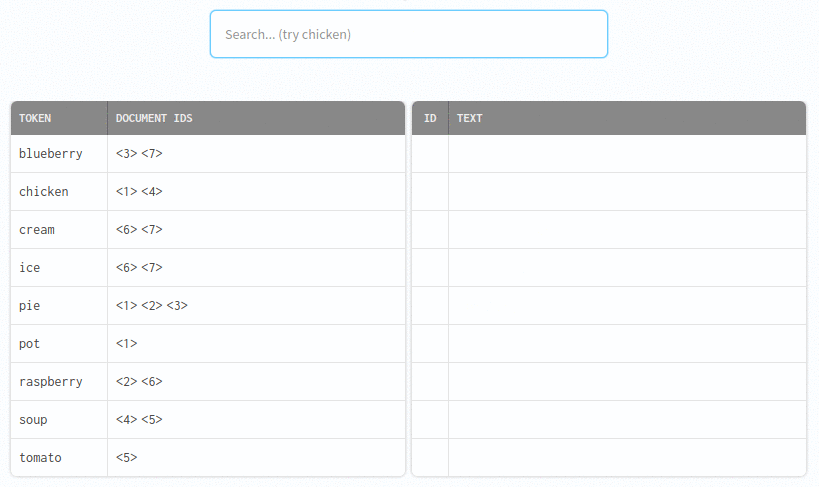
The search engine quickly finds records for matching tokens.
Chapter 4
Coming soon!

We've just scratched the surface of search technology,
and will continue to add chapters to The Story of Search.
New chapters will covers things like relevancy,
analysis, and getting started with open source engines.
Until then...

&
Send Feedback
(we'd love to hear from you!)